Overview
The standard paradigm for improving instruction following policies involves manually collecting additional robot data, labelling it with language instructions, and then finetuning the policy on this data. This process is expensive, and hard to scale up without huge human effort. Can we instead deploy robot fleets to collect large-scale datasets without human supervision, and use that data to self-improve the policy?
We propose a particular formulation of an autonomous improvement loop, which we call SOAR, that enables self-improvement of a multi-task language-conditioned policy. The key ideas are:
- Use VLMs and diffusion models to help guide large-scale autonomous data collection.
- Decouple language understanding from robotic control, so semantic understanding benefits from internet-scale pre-training and low-level control improve with self-supervision.
SOAR decouples a language-conditioned policy into an image-goal conditioned policy and a language-conditioned image subgoal generator. The benefit of such a formulation is that any autonomously collected data can be used to improve the policy with an entirely self-supervised learning algorithm, namely hindsight-relabeled goal-conditioned learning.
Autonomous data collection can then build off of the Internet-scale knowledge stored in VLMs and diffusion models. VLMs can be used as task proposers to guide the policy towards semantically interesting goals, and can automate the success detection of autonomously collected trajectories. Diffusion models can be used to synthesize interesting and diverse image goals from the semantic goals generated by the VLM. Both of these components help guide data collection towards interesting yet diverse tasks.
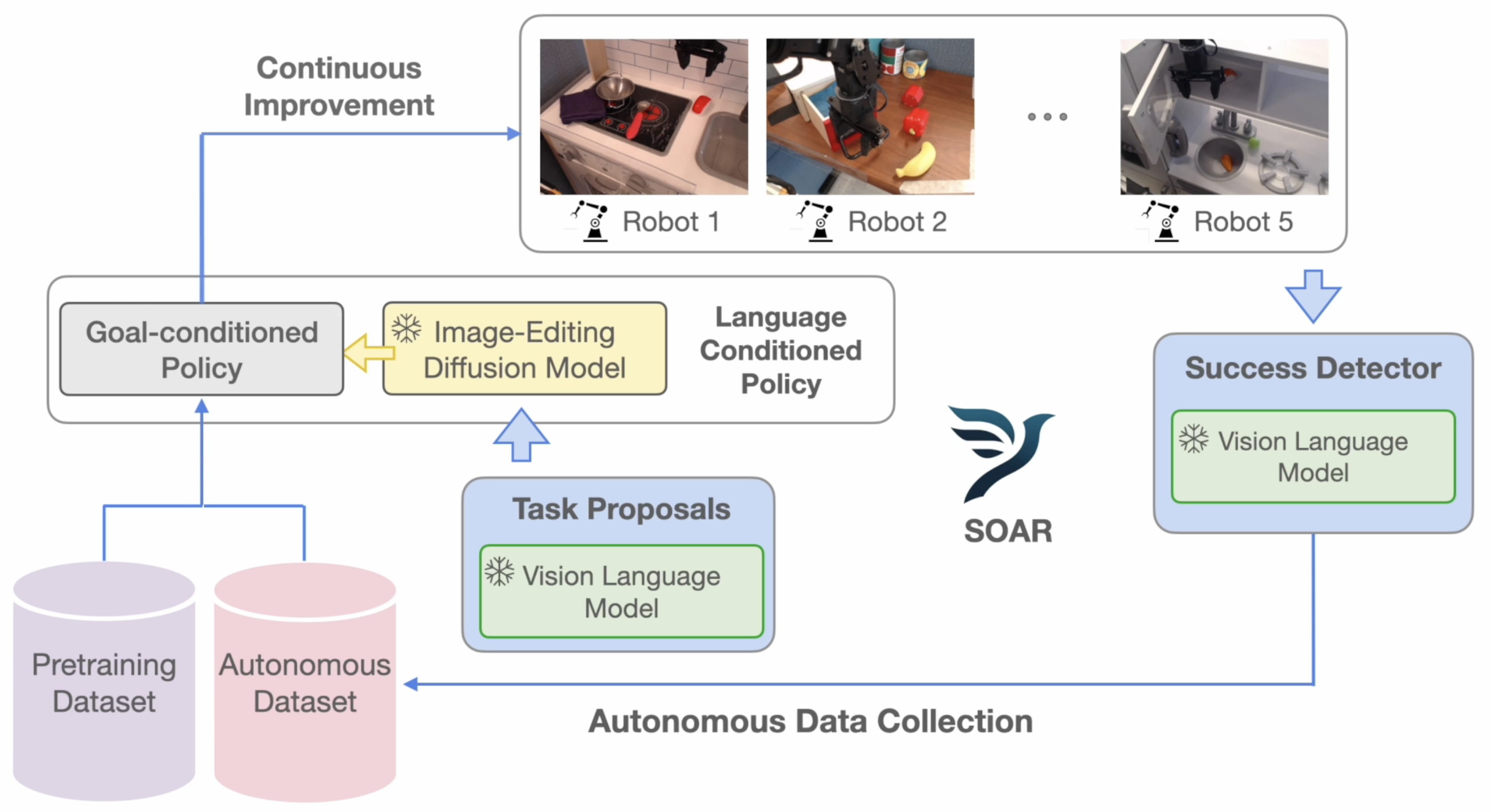
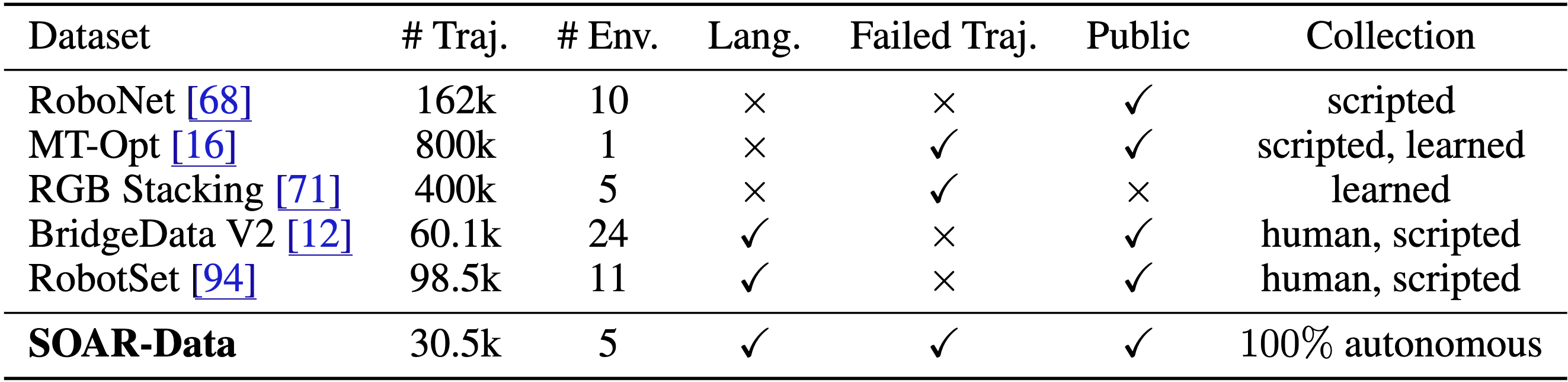
Putting these components together, SOAR becomes an end-to-end system for autonomous improvement. We deployed SOAR on a fleet of 5 WidowX robots, enabling the collection of over 30,000 autonomous trajectories across more than 50 scenes within just a few weeks, and evaluated its ability to achieve a 2x improvement in multiple language skills across 10 test scenes.
After running SOAR, the policy succeeds at tasks where it once failed.
Time lapse videos of autonomous data collection. Generated subgoal images during data collection are depicted in the top right
We decompose SOAR's instruction-following policy into an image-goal conditioned policy and SuSIE, an InstructPix2Pix-style language-conditioned image-editing diffusion model. Language task commands from the VLM are converted into subgoal images with the diffusion model, after which the goal conditioned policy is rolled out for a fixed number of timesteps. Then, a new subgoal is generated with the same language instruction, and the process repeats until the end of the trajectory.
In the context of autonomous improvement, such a formulation is very useful. Semantics are separated from motor skills, allowing the former to leverage cheap Internet-data and the latter cheap autonomously collected robot data. Goal-conditioned learning utilizes a denser learning signal than language-conditioned learning, and can better leverage suboptimal autonomous data. And the goal conditioned policy can be trained with a purely self-supervised objective, in contrast to a direct language conditioned policy, which would require a separate model to hindsight relabel autonomous trajectories with the ground truth language.
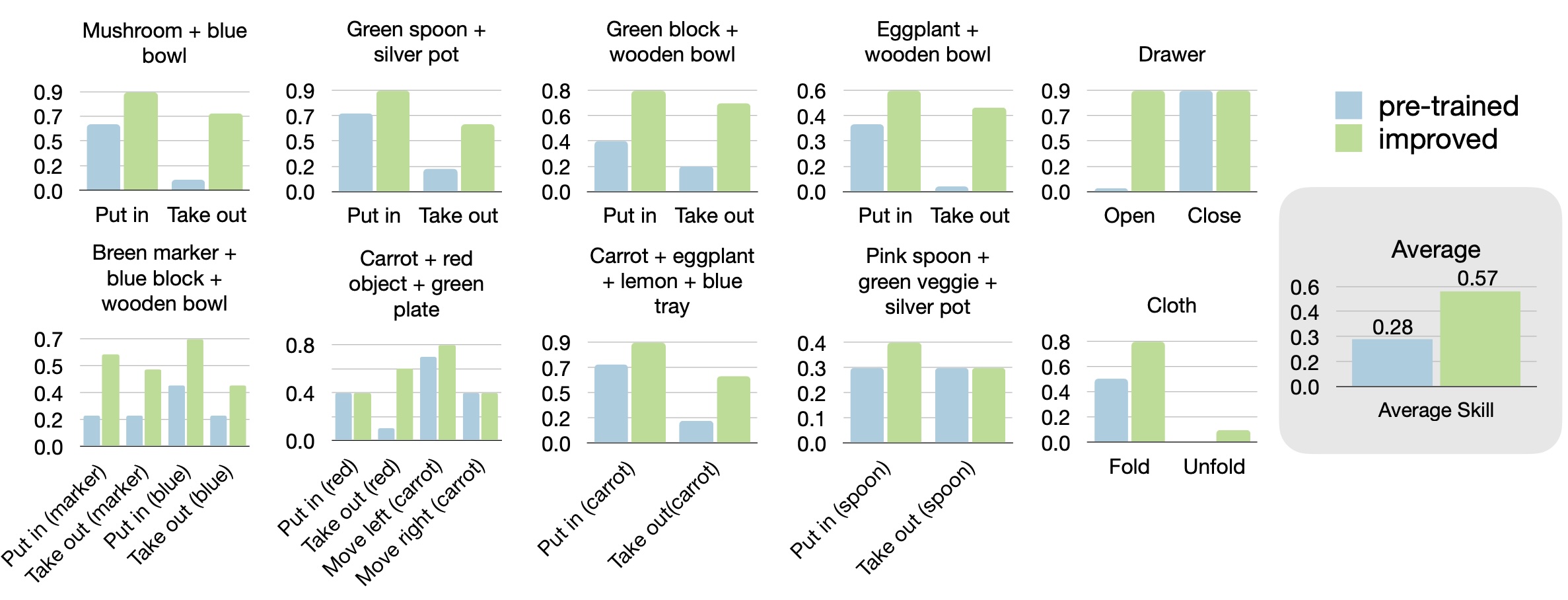
To evaluate the improvement capabilities of SOAR, we test the system on 10 different scenes, evaluating its ability to autonomously collect semantically relevant data and then learn from it. Improvement reflects the effectiveness of both the learning and data collection procedures; if data relevant to the skills being tested has not been collected, improvement will not occur. We find that SOAR enables ,on average, a a 2x improvement in multiple language skills across each of the 10 scenes.
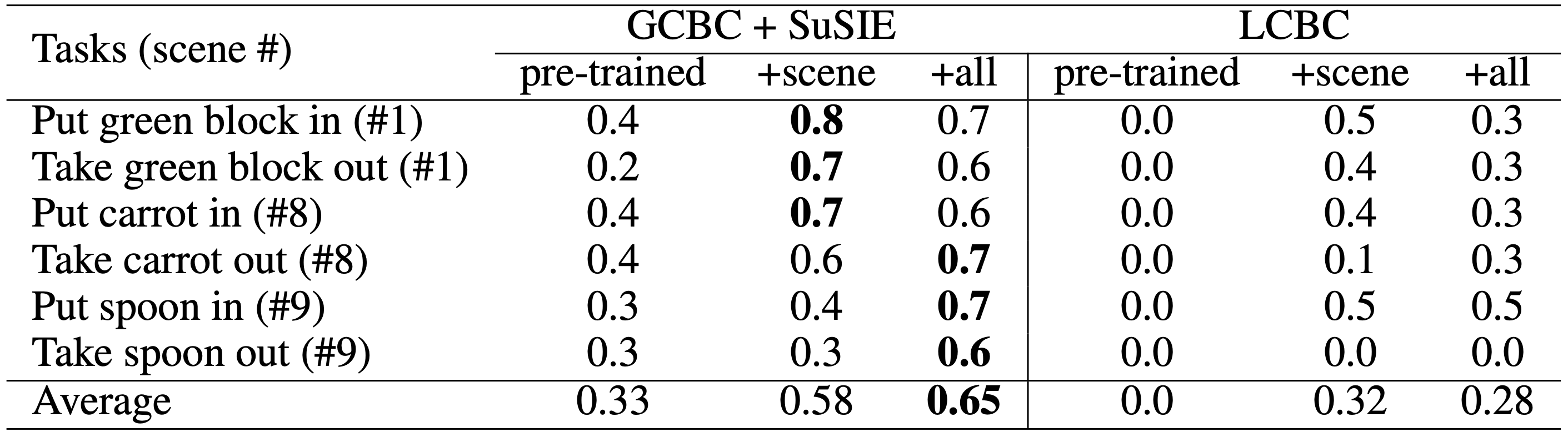
We observe that more autonomous data leads to better improvement. Training a single generalist policy on all the autonomously collected data across the 10 test scenes boosts the average success rate from 58% to 65%. We then investigate whether the decomposed, language-conditioned policy, GCBC+SuSIE, is truly necessary. To explore this, we compare it with a direct language-conditioned behavior cloning (LCBC) policy, trained on the same autonomous data collected by GCBC+SuSIE. While LCBC also improves performance, the decomposed policy in SOAR achieves much better results (65% vs 28%). We attribute this to goal-conditioned learning's ability to turn suboptimal autonomous trajectories into optimal objectives for reaching hindsight goals.
BibTeX
@article{zhou2024autonomous,
title={Autonomous Improvement of Instruction Following Skills via Foundation Models},
author={Zhiyuan Zhou and Pranav Atreya and Abraham Lee and Homer Walke and Oier Mees and Sergey Levine},
journal = {arXiv preprint arXiv:407.20635},
year={2024},
}